What is Feature-engine?
Feature-engine, a Python library for feature engineering
5 min read
Published Oct 3 2025
Guide Sections
Guide Comments

Feature-engine official website
Link to Feature-engine's official website and full documentation.
What is Feature-engine?
Feature-engine is an open-source Python library for feature engineering that integrates seamlessly with scikit-learn pipelines. It provides transformers for common preprocessing tasks (imputation, encoding, discretisation, outlier handling, etc.) using the fit() / transform() pattern: parameters are learned from training data and then applied consistently to new data. Unlike raw pandas operations, Feature-engine stores these learned parameters, and unlike some scikit-learn transformers, it preserves DataFrame structure — keeping column names and order. You can also target specific variables directly without extra slicing or ColumnTransformer.
Machine learning process essentials and feature engineering
To explain what feature engineering is and the role that Feature-engine fulfils, here is a high-level overview of the machine learning process.
At its core, machine learning is about teaching a computer to find patterns in data so it can make predictions or decisions without being explicitly programmed.
Instead of writing rules yourself (“if X, then Y”), you feed the computer examples of inputs and outputs, and it learns the rules on its own.
Example scenario:
Suppose we have a dataset with columns: Car Make, Car Model, Year of Manufacture, Mileage, and Resale Price.
We want to train a machine learning model that, given new values for Car Make, Car Model, Year, and Mileage, can predict the Resale Price.
Train/Test Split:
To evaluate the model properly, we split the dataset into two parts:
- Training set (typically 70–80%) → used to train the model.
- Test set (typically 20–30%) → used to evaluate performance.
In scikit-learn, this is done with train_test_split:
- X = input features (Car Make, Car Model, Year, Mileage) — usually a pandas DataFrame.
- y = target/label (Resale Price) — usually a pandas Series.
- test_size=0.2 → 20% test, 80% train.
- random_state=42 → makes the split reproducible.
This returns:
X_train→ training featuresX_test→ test featuresy_train→ training targetsy_test→ test targets
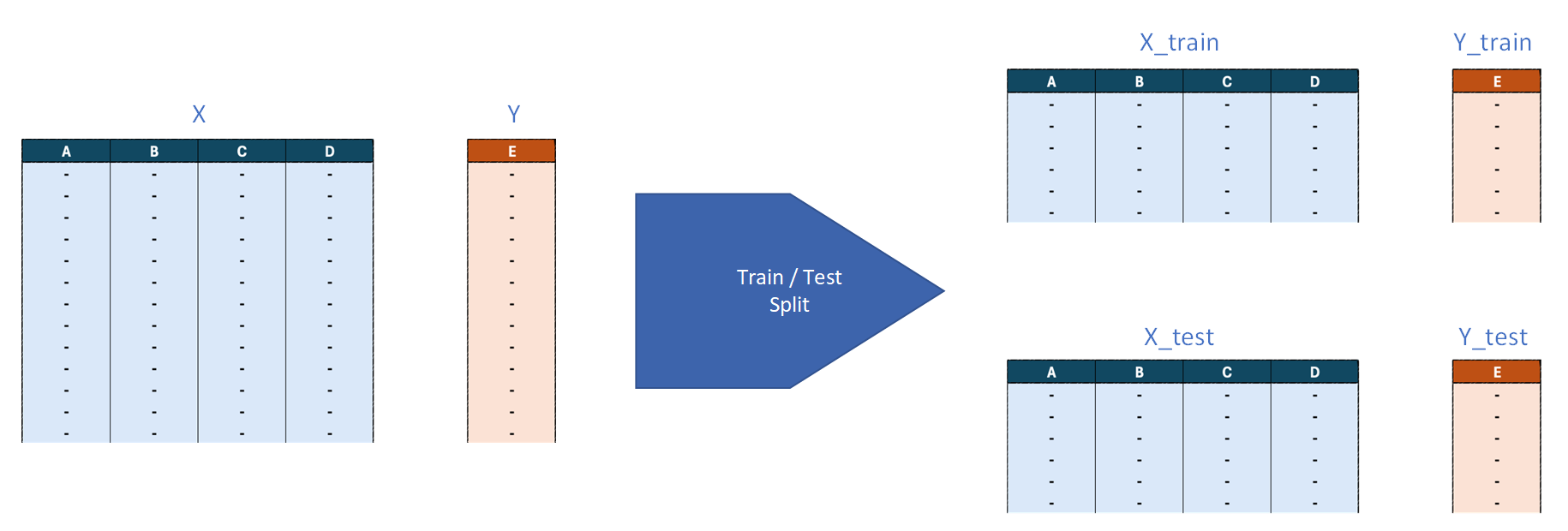
Graphic demonstrating the splitting of test and training data.
Feature Engineering
Before training, we need to process the data so the model can understand it.
Feature engineering may involve:
- Handling missing values
- Encoding categorical variables
- Scaling or transforming numerical features
- Discretising variables
- Detecting/removing outliers
While pandas provides many tools for these tasks, it does not “remember” what was learned from the training data. For example, if you fill missing values with a column mean using pandas, you’d have to manually calculate and reapply the same mean when processing new data.
Feature-engine solves this by wrapping transformations in classes that follow the fit() / transform() pattern:
- On
fit(), the transformer learns parameters from the training set (e.g., the mean for imputation, categories for encoding). - On
transform(), it applies those same parameters to the test set or new data.
Example: If you impute missing values in Mileage with the training set mean, that mean is stored. When processing the test set or future data, the same mean is used — not recalculated. This is what “learning parameters” means.
End-to-End Process:
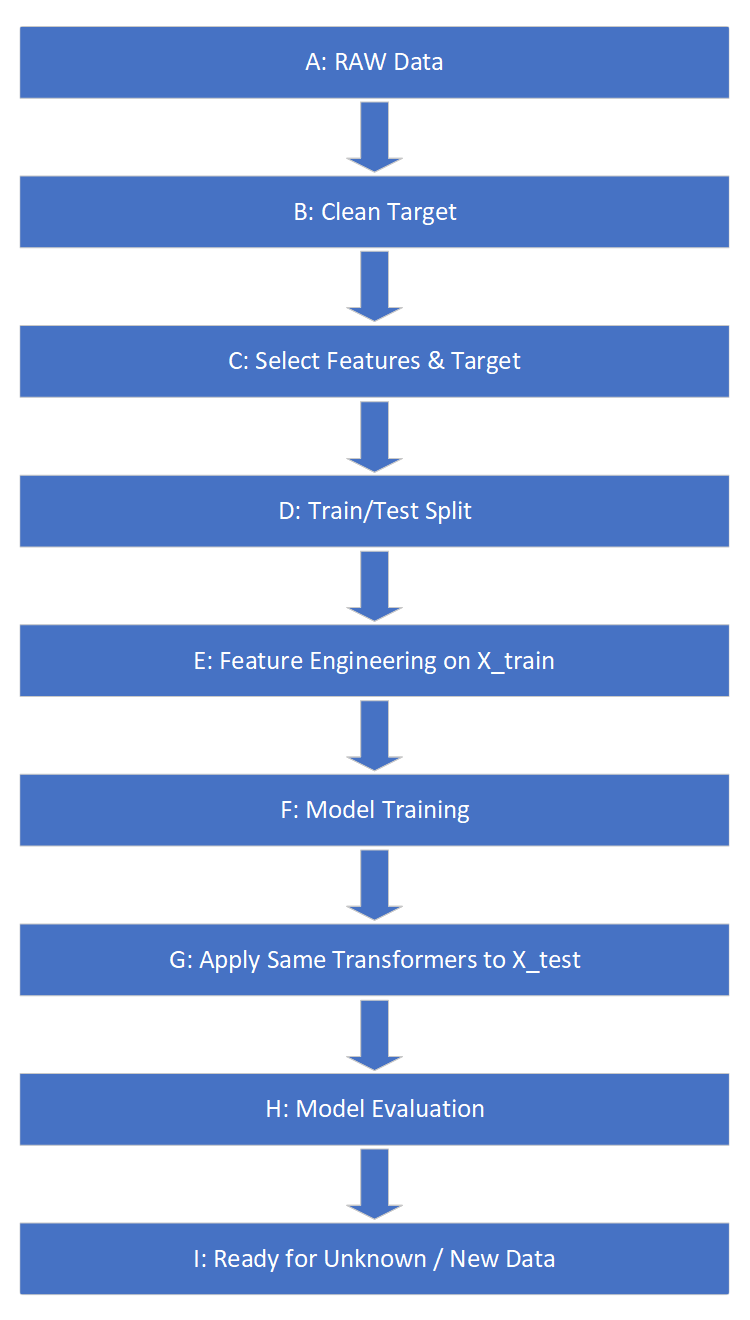
- A. Source raw data
B. Clean target (y) → remove rows with missing or invalid target values (e.g., missing/negative resale prices).
C. Select features & target → X = [Car Make, Car Model, Year, Mileage], y = [Resale Price].
D. Train/Test split
E. Feature engineering on X_train → imputation, encoding, scaling, etc.
F. Train model → fit onX_trainandy_train.
G. Apply same transforms to X_test using parameters learned from training.
H. Evaluate model → predict onX_testand compare toy_test.
I. Deploy model → for new data, apply the same feature engineering pipeline, then predict resale price.
Role of Feature-engine:
Feature-engine provides ready-to-use transformers for step E (feature engineering).
Because these transformers remember the parameters learned during training, they can also be applied in G (test set transformation) and I (new data) — ensuring consistency across the entire machine learning workflow.
The benefits of using Feature-engine
While scikit-learn includes its own transformers, they typically work with NumPy arrays and often drop DataFrame labels, which makes tracking changes harder. Feature-engine builds on scikit-learn’s framework but adds several practical advantages:
- Rich collection of transformers → includes not just the basics (imputation, encoding, scaling) but also more advanced options like end-tail imputation, decision-tree based discretisation, and feature selection methods.
- DataFrame in, DataFrame out → transformations preserve column names and structure, making debugging and downstream analysis much easier.
- Direct variable selection → you can specify exactly which columns each transformer applies to, without complex slicing or workarounds like
ColumnTransformer. - Seamless scikit-learn compatibility → fully integrates with pipelines, cross-validation, and grid search.
- Built-in alerts and validation → many transformers automatically check for invalid operations (e.g. log on negative values, divide by zero) and raise clear errors or warnings, preventing silent mistakes.
In short, Feature-engine combines the robustness of scikit-learn’s workflow with the usability of pandas, making feature engineering cleaner, safer, and easier to maintain.
Potential Limitations and Considerations
Feature-engine adds a lot of convenience, but there are some points to keep in mind:
- Not all transformations included → while comprehensive, domain-specific or very custom feature engineering steps may still require manual coding.
- Performance on large datasets → advanced methods (e.g. shuffling-based feature selection, recursive addition) can be computationally heavy, and DataFrame-level operations add overhead compared to raw NumPy arrays.
- Learning curve for parameters → each transformer has its own settings and assumptions (e.g. how unseen categories are handled in encoding, how outlier capping is applied), which must be understood to avoid issues in production.
- Pipeline complexity → overlapping functionality with other preprocessing tools can cause redundancy or conflicts, so pipeline order and design need careful consideration.
In practice, Feature-engine works best as a powerful extension to scikit-learn pipelines, but for very large-scale or highly domain-specific projects, a mix of Feature-engine, custom code, and low-level optimisations may still be required.
Products from our shop
Docker Cheat Sheet - Print at Home Designs

Docker Cheat Sheet Mouse Mat

Docker Cheat Sheet Travel Mug

Docker Cheat Sheet Mug
Vim Cheat Sheet - Print at Home Designs

Vim Cheat Sheet Mouse Mat

Vim Cheat Sheet Travel Mug

Vim Cheat Sheet Mug

SimpleSteps.guide branded Travel Mug

Developer Excuse Javascript - Travel Mug

Developer Excuse Javascript Embroidered T-Shirt - Dark

Developer Excuse Javascript Embroidered T-Shirt - Light

Developer Excuse Javascript Mug - White

Developer Excuse Javascript Mug - Black

SimpleSteps.guide branded stainless steel water bottle

Developer Excuse Javascript Hoodie - Light
