Core Algorithms: Clustering and Trees
Machine Learning Fundamentals with Python
3 min read
Published Nov 16 2025
Guide Sections
Guide Comments
In this section, you’ll learn two very different yet essential approaches in machine learning:
- How to group similar data points automatically (K-Means Clustering).
- How to make decisions and predictions using tree-based models.
K-Means Clustering (Unsupervised Learning)
K-Means is a simple and powerful unsupervised algorithm that groups data points into K clusters.
Each cluster is defined by its centroid (the average position of all points in that group).
It works like this:
- Choose the number of clusters (K).
- Randomly place K centroids.
- Assign each data point to the nearest centroid.
- Move each centroid to the mean of its assigned points.
- Repeat until the centroids stop moving (converge).
Example: Clustering Customers by Spending Behaviour
Output:

Explanation:
- Each customer is represented as a point in 2D space.
- The algorithm automatically divides them into two clusters (low spenders vs high spenders).
- The red X marks show the cluster centres (averages).
Choosing the Right Number of Clusters (Elbow Method)
We can plot the “inertia” (sum of distances to the nearest centroid) for different K values.
The point where inertia starts to flatten out (the “elbow”) is usually a good choice for K.

Explanation:
- If K = 1, all points are in one big cluster (high inertia).
- As K increases, inertia decreases.
- After the “elbow,” adding more clusters gives little improvement.
Decision Trees (Supervised Learning)
Decision Trees are supervised models that split data step by step based on feature values.
They ask a sequence of “yes/no” questions to make predictions.
Example:
Each split tries to make the resulting groups purer — that is, more uniform in their labels.
Example: Predicting if Someone Buys a Product
Output:
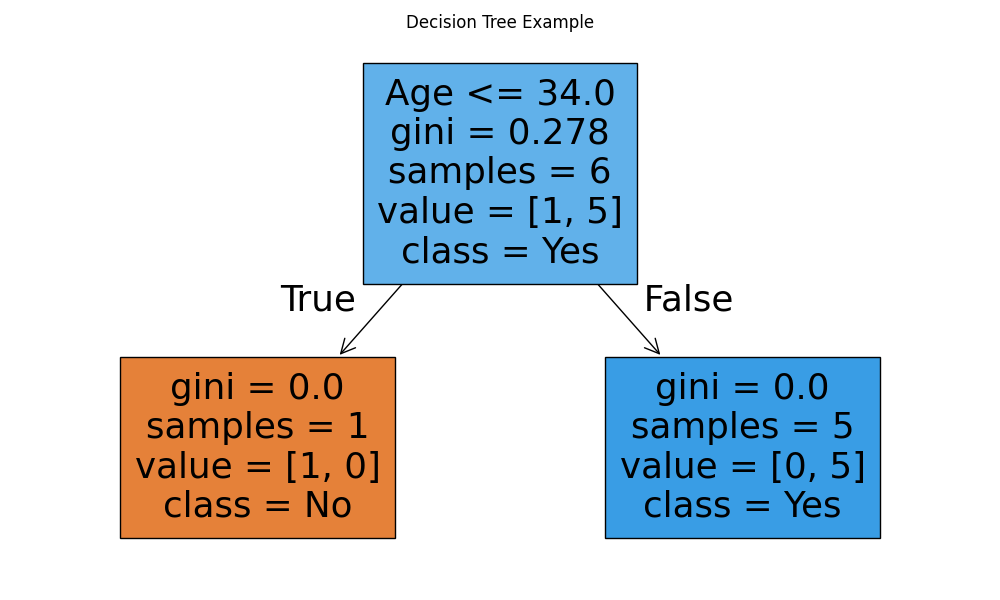
Explanation:
- The model finds rules that best separate people who buy vs don’t buy.
- The tree’s structure shows how decisions are made.
max_depthcontrols how deep (complex) the tree can grow.
Random Forests (Many Trees Combined)
A Random Forest is a collection (ensemble) of many decision trees.
Each tree sees a slightly different subset of the data, and their predictions are combined (majority vote).
Benefits:
- Reduces overfitting.
- Increases accuracy and robustness.
- Works well “out of the box.”
Example: Using a Random Forest
Explanation:
n_estimators=100means we use 100 trees.- Each tree votes, and the majority decision becomes the final prediction.
- Random forests handle messy real-world data better than a single tree.
Comparing Clustering and Trees
Aspect | K-Means | Decision Tree / Random Forest |
Type | Unsupervised | Supervised |
Goal | Group similar data | Predict target labels |
Output | Cluster assignments | Class labels / probabilities |
Requires labels? | No | Yes |
Example | Segmenting customers | Predicting if someone buys |
Products from our shop
Docker Cheat Sheet - Print at Home Designs

Docker Cheat Sheet Mouse Mat

Docker Cheat Sheet Travel Mug

Docker Cheat Sheet Mug
Vim Cheat Sheet - Print at Home Designs

Vim Cheat Sheet Mouse Mat

Vim Cheat Sheet Travel Mug

Vim Cheat Sheet Mug

SimpleSteps.guide branded Travel Mug

Developer Excuse Javascript - Travel Mug

Developer Excuse Javascript Embroidered T-Shirt - Dark

Developer Excuse Javascript Embroidered T-Shirt - Light

Developer Excuse Javascript Mug - White

Developer Excuse Javascript Mug - Black

SimpleSteps.guide branded stainless steel water bottle

Developer Excuse Javascript Hoodie - Light
