Core Algorithms: Regression
Machine Learning Fundamentals with Python
4 min read
Published Nov 16 2025
Guide Sections
Guide Comments
Regression is one of the most fundamental concepts in machine learning. It’s all about finding the relationship between variables — specifically, how input features affect an output value.
What Is Regression?
Regression predicts continuous (numeric) outcomes.
Example:
- Predicting house prices based on features like size or location.
- Predicting sales revenue given advertising spend.
- Predicting student scores from hours studied.
Linear Regression – The Basics
Idea:
Fit a straight line (or hyperplane in higher dimensions) that best predicts the target variable.
Formula for simple linear regression:
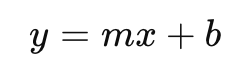
Where:
- y = predicted value
- x = input feature
- m = slope (coefficient)
- b = intercept (bias)
Scikit-learn automatically calculates these for you.
Example: Predicting House Prices:
Output:
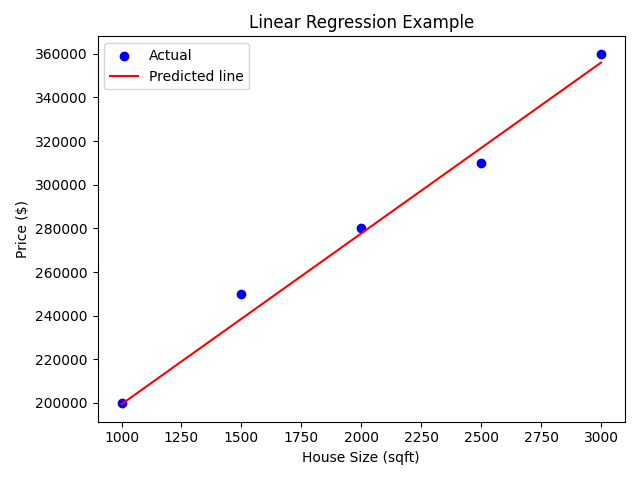
Explanation:
- We fitted a straight line that best represents the relationship between house size and price.
- The slope tells how much the price increases per additional square foot.
- The intercept tells the estimated price when size = 0 (theoretically).
Evaluating Regression Performance
We measure how well a regression model predicts actual values using metrics such as:
- MAE (Mean Absolute Error) : Average of absolute errors
- Good values - Small number (close to 0), meaning your predictions are, on average, very close to the actual values.
- Good depends on the target scale, eg. If house prices are around £300,000, an MAE of £5,000 is great, however, if house prices are around £100, an MAE of £5,000 is awful.
- Bad values - Large number, predictions are far off.
- MSE (Mean Squared Error) : Average of squared errors (penalises big mistakes)
- Good values - Small number, often much smaller than the square of your target values.
- Bad values - Large number, indicates large mistakes or many medium-sized mistakes.
- RMSE (Root Mean Squared Error) : Square root of MSE (same units as target)
- Good values - Small, relative to typical values in your dataset. RMSE ≈ MAE → errors consistent (good sign).
- Bad values - Large, especially compared to the dataset’s typical values. RMSE > MAE → the model is making occasional very bad mistakes.
- R² (Coefficient of Determination) : How much of the variation in the target the model explains.
- Good values - 0.70 – 1.0 → strong predictive power, 1.0 → perfect (rare in real life)
- Bad values - 0.0 → model is no better than predicting the mean, Negative value → model is worse than the baseline.
- Guidelines:
> 0.9→ excellent (common in physics, rare in social sciences)0.6 – 0.8→ solid model0.3 – 0.6→ fair (useful but not great)0.0 – 0.3→ weak model< 0→ actively bad model
Example:
Logistic Regression – When Outputs Are Categories
Despite the name, logistic regression is used for classification, not regression. It predicts the probability that an input belongs to a certain class (e.g., spam or not spam).
The logistic function (sigmoid) converts linear output into a probability between 0 and 1:
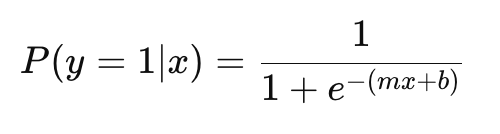
If P>0.5, predict 1 (positive class); otherwise 0.
Example: Predicting If a Student Passes an Exam:
Output:
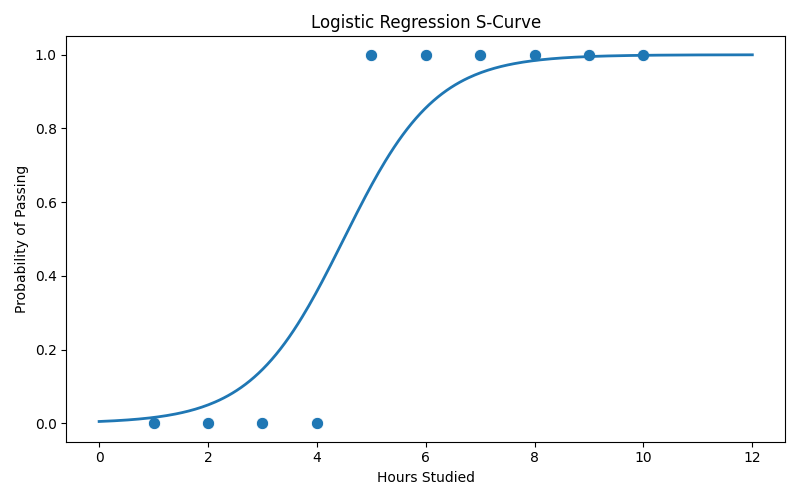
Explanation:
- Predictions - these are the model’s final yes/no guesses (1 = pass, 0 = fail) for the students in the test set.
- Probabilities - for each student, logistic regression gives two probabilities:
- Column 0 → likelihood of failing
- Column 1 → likelihood of passing
- The prediction (
0or1) is whichever probability is higher. This shows how confident the model is.
- Accuracy - % of test predictions the model got correct.
- Confusion matrix - [[TN, FP], [FN, TP]] tells you exactly where mistakes happened:
- TN (true negatives): correctly predicted fails
- FP (false positives): predicted pass but actually failed
- FN (false negatives): predicted fail but actually passed
- TP (true positives): correctly predicted passes
- Classification Report - more detailed view than accuracy alone, for each class (0 = fail, 1 = pass):
- Precision: when the model predicts pass/fail, how often is it right?
- Recall: how well the model finds all actual passes/fails
- F1-score: combined measure of precision + recall
- Support: number of true examples of each class
Comparing Linear vs Logistic Regression
Aspect | Linear Regression | Logistic Regression |
Output | Continuous numeric value | Probability (0–1) |
Used for | Regression problems | Classification problems |
Example | Predicting house price | Predicting if an email is spam |
Function | Straight line | Sigmoid (S-shaped curve) |
Products from our shop
Docker Cheat Sheet - Print at Home Designs

Docker Cheat Sheet Mouse Mat

Docker Cheat Sheet Travel Mug

Docker Cheat Sheet Mug
Vim Cheat Sheet - Print at Home Designs

Vim Cheat Sheet Mouse Mat

Vim Cheat Sheet Travel Mug

Vim Cheat Sheet Mug

SimpleSteps.guide branded Travel Mug

Developer Excuse Javascript - Travel Mug

Developer Excuse Javascript Embroidered T-Shirt - Dark

Developer Excuse Javascript Embroidered T-Shirt - Light

Developer Excuse Javascript Mug - White

Developer Excuse Javascript Mug - Black

SimpleSteps.guide branded stainless steel water bottle

Developer Excuse Javascript Hoodie - Light
