Full Example: Titanic Dataset
Machine Learning Fundamentals with Python
1 min read
This section is 1 min read, full guide is 29 min read
Published Nov 16 2025
10
Show sections list
0
Log in to enable the "Like" button
0
Guide comments
0
Log in to enable the "Save" button
Respond to this guide
Guide Sections
Guide Comments
ClusteringImagesK-MeansLinear RegressionLogistic RegressionMachine LearningNeural NetworksNLPNumPyPythonRandom Forestsscikit-learnSupervised LearningUnsupervised Learning
Here is an example that uses the Titanic dataset from Seaborn, does some basic cleaning and EDA, trains the model, saves and loads the model and then uses it to make a prediction from fresh unseen data.
Python code:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
import joblib
# Load titanic dataset
df = sns.load_dataset('titanic')
# Show basic info
print(df.head())
print("\nShape:", df.shape)
print("\nMissing values:\n", df.isnull().sum())
# Handle missing values
df['age'].fillna(df['age'].median(), inplace=True)
df['embarked'].fillna(df['embarked'].mode()[0], inplace=True)
# Select relevant features
df = df[['pclass', 'sex', 'age', 'sibsp', 'parch', 'fare', 'embarked', 'survived']]
# Encode categorical features
encoder = LabelEncoder()
# male=1, female=0
df['sex'] = encoder.fit_transform(df['sex'])
df['embarked'] = encoder.fit_transform(df['embarked'])
# Separate features and target
X = df.drop(columns=['survived'])
y = df['survived']
# Scale numeric features
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, test_size=0.2, random_state=42
)
print("Training set:", X_train.shape)
print("Test set:", X_test.shape)
# Train Random Forest Classifier
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# Evaluate the model performance
y_pred = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
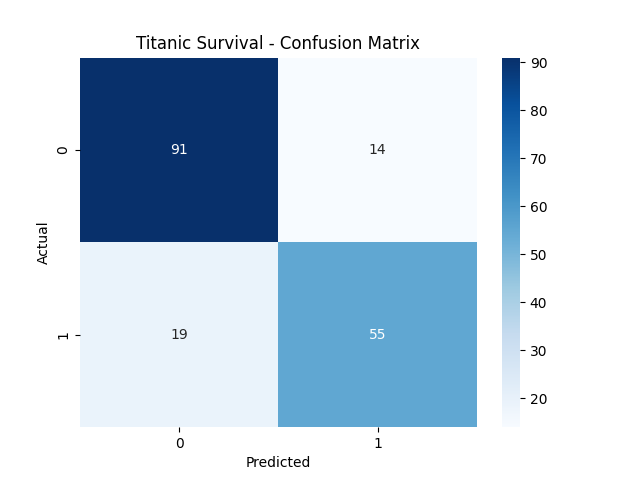
# Confusion matrix visualization
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title("Titanic Survival - Confusion Matrix")
plt.show()
# Hyperparameter Tuning
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [4, 6, 8, None],
'min_samples_split': [2, 5, 10]
}
grid_search = GridSearchCV(
RandomForestClassifier(random_state=42),
param_grid,
cv=5,
scoring='accuracy',
n_jobs=-1
)
grid_search.fit(X_train, y_train)
print("Best Parameters:", grid_search.best_params_)
print("Best Cross-Validation Accuracy:", grid_search.best_score_)
# Save model and scaler
joblib.dump(model, "titanic_model.joblib")
joblib.dump(scaler, "titanic_scaler.joblib")
# Later, reload them like this:
loaded_model = joblib.load("titanic_model.joblib")
loaded_scaler = joblib.load("titanic_scaler.joblib")
# Make predictions with the loaded model
# Example new passenger
new_passenger = pd.DataFrame({
'pclass': [2],
# male
'sex': [1],
'age': [30],
'sibsp': [0],
'parch': [0],
'fare': [50.0],
'embarked': [1]
})
# Scale and predict
new_scaled = loaded_scaler.transform(new_passenger)
prediction = loaded_model.predict(new_scaled)
print("Predicted survival:", "Survived" if prediction[0] == 1 else "Did not survive")
Copy to Clipboard
Toggle show comments
Output:
survived pclass sex age sibsp parch fare embarked class who adult_male deck embark_town alive alone
0 0 3 male 22.0 1 0 7.2500 S Third man True NaN Southampton no False
1 1 1 female 38.0 1 0 71.2833 C First woman False C Cherbourg yes False
2 1 3 female 26.0 0 0 7.9250 S Third woman False NaN Southampton yes True
3 1 1 female 35.0 1 0 53.1000 S First woman False C Southampton yes False
4 0 3 male 35.0 0 0 8.0500 S Third man True NaN Southampton no True
Shape: (891, 15)
Missing values:
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
dtype: int64
Training set: (712, 7)
Test set: (179, 7)
Accuracy: 0.8156424581005587
Classification Report:
precision recall f1-score support
0 0.83 0.87 0.85 105
1 0.80 0.74 0.77 74
accuracy 0.82 179
macro avg 0.81 0.80 0.81 179
weighted avg 0.81 0.82 0.81 179
Best Parameters: {'max_depth': 6, 'min_samples_split': 5, 'n_estimators': 200}
Best Cross-Validation Accuracy: 0.8314192849404117
Predicted survival: Did not survive
Products from our shop
Docker Cheat Sheet - Print at Home Designs

Docker Cheat Sheet Mouse Mat

Docker Cheat Sheet Travel Mug

Docker Cheat Sheet Mug
Vim Cheat Sheet - Print at Home Designs

Vim Cheat Sheet Mouse Mat

Vim Cheat Sheet Travel Mug

Vim Cheat Sheet Mug

SimpleSteps.guide branded Travel Mug

Developer Excuse Javascript - Travel Mug

Developer Excuse Javascript Embroidered T-Shirt - Dark

Developer Excuse Javascript Embroidered T-Shirt - Light

Developer Excuse Javascript Mug - White

Developer Excuse Javascript Mug - Black

SimpleSteps.guide branded stainless steel water bottle

Developer Excuse Javascript Hoodie - Light
