Model Evaluation and Performance Analysis
Machine Learning Fundamentals with Python
3 min read
Published Nov 16 2025
Guide Sections
Guide Comments
Why Evaluate Models?
Building a model is only half the job — the other half is knowing how well it performs.
Evaluation tells us:
- How accurate and reliable the model is
- Whether it’s overfitting or underfitting
- How it might behave on unseen, real-world data
The key principle:
Always evaluate on data your model hasn’t seen before (the test set).
Regression Model Metrics
When your model predicts continuous values (like prices or scores), you can use these metrics:
MAE (Mean Absolute Error)- Average absolute difference between predictions and true values.MSE (Mean Squared Error)- Average of squared errors (penalises large mistakes).RMSE (Root Mean Squared Error)- Square root of MSE (same units as target).R² (Coefficient of Determination)- How much variance in data is explained.
Example: Evaluating a Regression Model
Output:
Explanation:
- MAE, MSE, and RMSE measure “how far off” predictions are.
- R² measures how much of the true variation your model explains.
Classification Model Metrics
When predicting categories e.g. “spam” or “not spam”, accuracy alone can be misleading, especially with unbalanced data.
Key Metrics:
Accuracy- Proportion of correct predictions.Precision- Of all predicted positives, how many were correct.Recall- Of all actual positives, how many were found.F1 Score- Harmonic mean of precision and recall (balances both).Confusion Matrix- Table showing counts of true/false positives/negatives.
Example: Binary Classification Evaluation
Output:
Explanation:
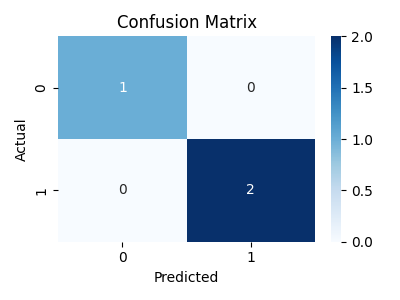
- The confusion matrix shows predictions vs actuals, [[TN FP], [FN TP]]:
- TN = True Negative (correctly predicted 0)
- TP = True Positive (correctly predicted 1)
- FP = False Positive (predicted 1 but should be 0)
- FN = False Negative (predicted 0 but should be 1)
- The classification report summarises all major metrics.
Visualising Performance with a Confusion Matrix
A heatmap makes it easy to spot where your model is making mistakes (e.g., mixing up similar classes).
ROC Curves and AUC
The ROC curve (Receiver Operating Characteristic) plots the tradeoff between True Positive Rate (Recall) and False Positive Rate.
The AUC (Area Under the Curve) gives a single measure of overall performance.
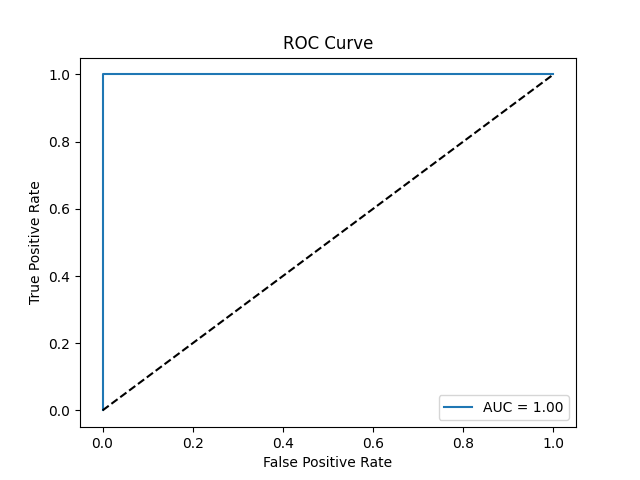
Interpretation:
- The closer the ROC curve is to the top-left corner, the better.
- AUC = 1.0 means perfect prediction; AUC = 0.5 means random guessing.
Cross-Validation
To make sure your model’s performance isn’t dependent on a single train/test split, you can use cross-validation.
Explanation:
- Cross-validation splits the data into multiple folds.
- The model trains and tests several times, reducing variance in performance estimates.
Model Tuning and Hyperparameter Optimisation
Most models have hyperparameters, settings that affect how they learn (like tree depth, number of clusters, learning rate, etc.).
You can search for the best combination using GridSearchCV or RandomizedSearchCV.
Explanation:
GridSearchCVtests every parameter combination.RandomizedSearchCVis faster for large search spaces.- Helps improve model accuracy and generalisation.
Products from our shop
Docker Cheat Sheet - Print at Home Designs

Docker Cheat Sheet Mouse Mat

Docker Cheat Sheet Travel Mug

Docker Cheat Sheet Mug
Vim Cheat Sheet - Print at Home Designs

Vim Cheat Sheet Mouse Mat

Vim Cheat Sheet Travel Mug

Vim Cheat Sheet Mug

SimpleSteps.guide branded Travel Mug

Developer Excuse Javascript - Travel Mug

Developer Excuse Javascript Embroidered T-Shirt - Dark

Developer Excuse Javascript Embroidered T-Shirt - Light

Developer Excuse Javascript Mug - White

Developer Excuse Javascript Mug - Black

SimpleSteps.guide branded stainless steel water bottle

Developer Excuse Javascript Hoodie - Light
