Model Evaluation and Validation
Scikit-learn Basics
4 min read
Published Nov 17 2025, updated Nov 19 2025
Guide Sections
Guide Comments
Building a model is only half the battle, the other half is knowing how well it actually works.
Model evaluation and validation help ensure that your model’s performance reflects true generalisation, not just how well it memorised the training data.
In Scikit-learn, evaluation and validation are integral parts of the machine-learning process.
You’ll use them to:
- Measure predictive performance with metrics
- Detect and prevent overfitting
- Compare models objectively
- Tune hyperparameters confidently
The Importance of Validation
When training a model, it’s easy to overestimate performance if you test it on the same data it was trained on.
This is called overfitting — the model fits the training data too closely and fails on unseen examples.
Two Key Concepts:
- Training Error: How well the model fits the data it learned from.
- Generalisation Error: How well it performs on new, unseen data.
Goal:
- Minimise generalisation error — not just training error.
- To estimate generalisation, we reserve a validation set or use cross-validation to simulate multiple training/testing cycles.
Train / Test Split
The simplest validation strategy is to divide the data into training and testing subsets.
Notes:
test_size=0.3reserves 30% of data for testing.random_stateensures reproducibility.- For classification, use
stratify=yto maintain class proportions.
While simple, a single split can be misleading if data is small or randomly unbalanced. That’s where cross-validation helps.
Cross-Validation (CV)
Cross-validation gives a more reliable estimate of model performance by splitting the data multiple times and averaging the results.
k-Fold Cross-Validation
Data is divided into k equal parts (“folds”):
- Train on k−1 folds
- Test on the remaining fold
- Repeat k times so each fold is used once as test data
Scikit-learn automates this with cross_val_score.
Example:
Output:
Notes:
cv=5→ five-fold CV (default for many functions).- Results are more robust because they average performance across splits.
- Use stratified CV for classification to preserve class ratios.
Stratified K-Fold (for classification)
Stratification prevents bias when class distributions are uneven, essential for imbalanced datasets.
Classification Metrics
Metric | Description | Scikit-learn Function |
Accuracy | Fraction of correct predictions |
|
Precision | True positives / (True + False Positives) |
|
Recall (Sensitivity) | True positives / (True + False Negatives) |
|
F1 Score | Harmonic mean of precision & recall |
|
ROC-AUC | Area under the ROC curve |
|
Example:
Regression Metrics
Metric | Description | Function |
MAE | Mean absolute error |
|
MSE | Mean squared error |
|
RMSE | Root of MSE |
|
R² Score | Proportion of variance explained |
|
Example:
Validation Curve
Shows model performance across a range of hyperparameter values.
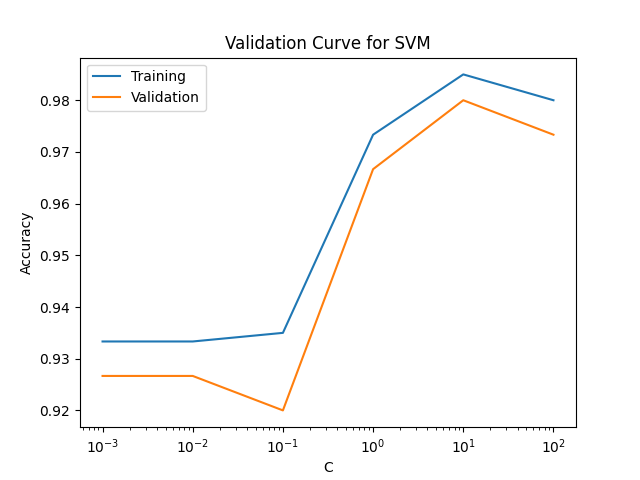
Interpretation:
- Large gap between train and validation = overfitting.
- Low performance on both = underfitting.
Learning Curve
Shows how model performance changes with training set size.
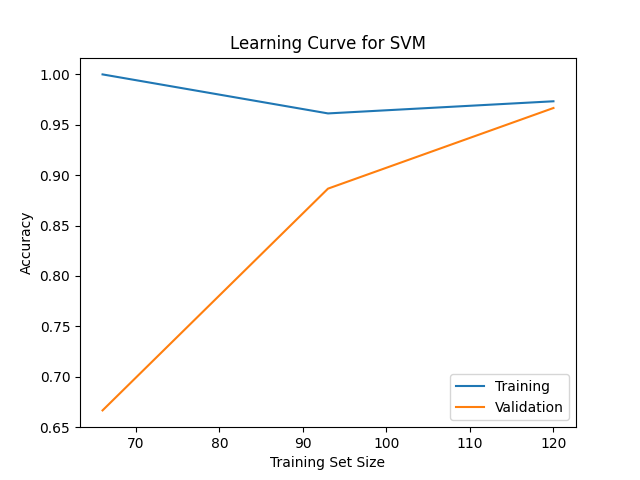
Use this to determine whether collecting more data would help or if the model is too complex.
Model Comparison
When multiple models perform similarly, you can use statistical techniques to compare them fairly.
Example comparing cross-validated scores:
Best practice:
Choose the simplest model that performs adequately, not the most complex.
Overfitting and Underfitting
Behaviour | Description | Typical Fix |
Underfitting | Model too simple, fails to capture patterns | Use a more complex model or add features |
Overfitting | Model too complex, memorises training data | Regularise, simplify model, or gather more data |
Visual check (conceptually):
- Overfit → low training error, high test error
- Underfit → high training and test error
Regularisation methods (like alpha in Ridge or C in SVM) directly control this balance.
Cross-Validation Best Practices
- Always use stratified folds for classification.
- Use cross-validation before reporting final performance.
- Never tune hyperparameters on the test set, use a separate validation split or nested CV.
- Use consistent random seeds for reproducibility.
- For small datasets, prefer Leave-One-Out CV (LOOCV) or repeated k-fold.
Products from our shop
Docker Cheat Sheet - Print at Home Designs

Docker Cheat Sheet Mouse Mat

Docker Cheat Sheet Travel Mug

Docker Cheat Sheet Mug
Vim Cheat Sheet - Print at Home Designs

Vim Cheat Sheet Mouse Mat

Vim Cheat Sheet Travel Mug

Vim Cheat Sheet Mug

SimpleSteps.guide branded Travel Mug

Developer Excuse Javascript - Travel Mug

Developer Excuse Javascript Embroidered T-Shirt - Dark

Developer Excuse Javascript Embroidered T-Shirt - Light

Developer Excuse Javascript Mug - White

Developer Excuse Javascript Mug - Black

SimpleSteps.guide branded stainless steel water bottle

Developer Excuse Javascript Hoodie - Light
