Supervised Learning
Scikit-learn Basics
4 min read
Published Nov 17 2025, updated Nov 19 2025
Guide Sections
Guide Comments
Supervised learning is the foundation of most practical machine-learning systems.
In this paradigm, a model learns from labeled data, examples where both the inputs (X) and the desired outputs (y) are known.
The model’s goal is to discover the relationship between input features and target outputs so that it can make accurate predictions on new, unseen data.
Supervised learning is divided into two main categories:
- Classification: Predicting discrete labels (e.g. “spam” or “not spam”).
- Regression: Predicting continuous numeric values (e.g. predicting house prices).
Throughout this section, we’ll explore both tasks, their key concepts, and how to implement them efficiently using Scikit-learn.
The Supervised Learning Workflow
A typical supervised learning process involves:
- Data Preparation - Split data into features (
X) and labels (y), then divide into training and testing subsets. - Model Selection - Choose an appropriate algorithm for the problem (e.g. logistic regression, random forest).
- Training - Fit the model to the training data using
.fit(X_train, y_train). - Prediction - Apply the model to unseen data using
.predict(X_test). - Evaluation - Measure performance using relevant metrics (accuracy, R², etc.).
- Tuning and Validation - Refine hyperparameters and verify generalisation via cross-validation.
Classification
Classification problems involve assigning data points to one of a set of discrete categories. The model learns a decision boundary that separates these classes based on feature patterns.
Examples:
- Spam filtering (spam / not spam)
- Disease diagnosis (positive / negative)
- Handwritten digit recognition (0–9)
Scikit-learn offers many classifiers, including:
LogisticRegressionKNeighborsClassifierDecisionTreeClassifierRandomForestClassifierSVC(Support Vector Classifier)GaussianNB(Naive Bayes)GradientBoostingClassifier
All follow the same API pattern: fit → predict → evaluate.
Example: Logistic Regression on Iris Dataset
Output:
Notes:
- Logistic regression is a baseline classification model, it performs well on linearly separable data.
max_iterensures convergence for larger datasets.- The confusion matrix provides a detailed breakdown of prediction performance across classes.
Example: Decision Tree Classifier
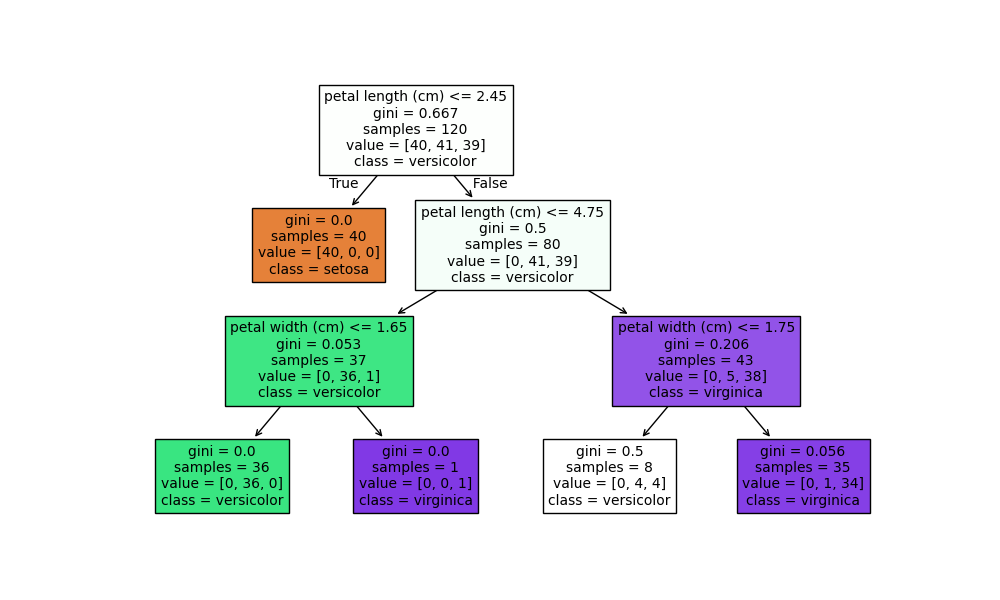
Notes:
- Decision trees are intuitive and interpretable.
- Limiting
max_depthhelps prevent overfitting. - Trees form the basis for powerful ensemble models like Random Forest and Gradient Boosting.
Key Classification Metrics
Metric | Description | Function |
Accuracy | Percentage of correctly predicted samples |
|
Precision | Proportion of positive predictions that were correct |
|
Recall | Proportion of actual positives that were correctly predicted |
|
F1-score | Harmonic mean of precision and recall |
|
ROC-AUC | Trade-off between true and false positive rates |
|
Example:
Regression
Regression models predict continuous numeric values. Instead of predicting discrete labels, they estimate quantities.
Examples:
- Predicting house prices
- Estimating sales, temperature, or life expectancy
Common regression algorithms:
LinearRegressionRidge,Lasso(regularised linear models)DecisionTreeRegressorRandomForestRegressorSVR(Support Vector Regressor)GradientBoostingRegressor
All regression estimators follow the same .fit() and .predict() pattern.
Example: Linear Regression
Notes:
- R² measures how well the model explains the variance in the data.
- MSE penalises larger errors more strongly, highlighting variance issues.
- Linear regression assumes linear relationships and normally distributed residuals.
Example: Random Forest Regressor
Notes:
- Random forests average predictions from multiple trees to reduce variance.
- They handle nonlinear data and mixed feature types well.
- Generally robust with minimal tuning.
Regression Metrics
Metric | Description | Function |
MAE (Mean Absolute Error) | Average absolute difference |
|
MSE (Mean Squared Error) | Average of squared differences |
|
RMSE | Square root of MSE |
|
R² Score | Proportion of variance explained |
|
Example:
Choosing and Comparing Models
There’s no one-size-fits-all algorithm, model selection depends on data size, feature relationships, and problem type.
Problem Type | Good Starting Model | Try Alternatives When... |
Binary classification | Logistic Regression | Data is nonlinear → SVM, RandomForest |
Multi-class classification | RandomForestClassifier | Dataset is large → GradientBoosting |
Regression | LinearRegression | Data is nonlinear → RandomForest, SVR |
Small dataset | KNN, DecisionTree | High-dimensional → Regularized models |
Scikit-learn makes model comparison easy with cross-validation
Common Pitfalls
- Skipping preprocessing - Unscaled features can bias distance-based algorithms (SVM, KNN).
- Using accuracy on imbalanced data - Use precision, recall, or F1-score instead.
- Forgetting to split data before training - Leads to data leakage and inflated performance metrics.
- Overfitting trees or ensembles - Limit depth or tune hyperparameters via cross-validation.
- Ignoring randomness - Always set
random_statefor reproducible results.
Best Practices
- Start simple, try linear models first to establish a baseline.
- Always separate training and test data before preprocessing.
- Compare multiple models and metrics before concluding.
- Regularise when working with high-dimensional data.
- Save the trained model only after validation.
Products from our shop
Docker Cheat Sheet - Print at Home Designs

Docker Cheat Sheet Mouse Mat

Docker Cheat Sheet Travel Mug

Docker Cheat Sheet Mug
Vim Cheat Sheet - Print at Home Designs

Vim Cheat Sheet Mouse Mat

Vim Cheat Sheet Travel Mug

Vim Cheat Sheet Mug

SimpleSteps.guide branded Travel Mug

Developer Excuse Javascript - Travel Mug

Developer Excuse Javascript Embroidered T-Shirt - Dark

Developer Excuse Javascript Embroidered T-Shirt - Light

Developer Excuse Javascript Mug - White

Developer Excuse Javascript Mug - Black

SimpleSteps.guide branded stainless steel water bottle

Developer Excuse Javascript Hoodie - Light
